前言
這里先說明一下�����,網(wǎng)上很多人說阿里規(guī)定500w數(shù)據(jù)就要分庫分表。實際上��,這個500w并不是定義死的�,而是與MySQL的配置以及機器的硬件有關。MySQL為了提升性能����,會將表的索引裝載到內(nèi)存中。但是當表的數(shù)據(jù)到達一定的量的時候���,會導致內(nèi)存無法存儲這些索引��,無法存儲索引�����,就只能進行磁盤IO��,從而導致性能下降���。
實戰(zhàn)調(diào)優(yōu)
我這里有張表��,數(shù)據(jù)有1000w���,目前只有一個主鍵索引
CREATE TABLE `user` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`uname` varchar(20) DEFAULT NULL COMMENT '賬號',
`pwd` varchar(20) DEFAULT NULL COMMENT '密碼',
`addr` varchar(80) DEFAULT NULL COMMENT '地址',
`tel` varchar(20) DEFAULT NULL COMMENT '電話',
`regtime` char(30) DEFAULT NULL COMMENT '注冊時間',
`age` int(11) DEFAULT NULL COMMENT '年齡',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10000003 DEFAULT CHARSET=utf8;

查詢所有大概16s?����?芍^是相當慢了�����。通常我們一個后臺系統(tǒng)�����,比如這個是一個電商平臺��,這個是用戶表。后臺管理系統(tǒng)�,一般會查詢這些用戶信息,做一些操作�����,比如后臺直接新增用戶啊����,或者刪除用戶啊這些操作。
所以這里就誕生了兩個需求����,一個是查詢count��,一個是分頁查詢
我們分別來測試一下count用的時間和分頁查詢所用的時間
select * from user limit 1, 10 //幾乎不用時
select * from user limit 1000000, 10 //0.35s
select * from user limit 5000000, 10 //1.7s
select * from user limit 9000000, 10 //2.8s
select count(1) from user //1.7s
從上面查詢所用時間可以看出來��,如果是分頁查詢的話�,查詢的數(shù)據(jù)越往后用時是越長的,查詢count也需要1.7s���。這顯然是不符合我們的要求的����。所以,這里我們就需要優(yōu)化���。首先我們這里進行索引優(yōu)化試試
首先看一下這是只有主鍵索引的執(zhí)行計劃:

alter table `user` add INDEX `sindex` (`uname`,`pwd`,`addr`,`tel`,`regtime`,`age`)
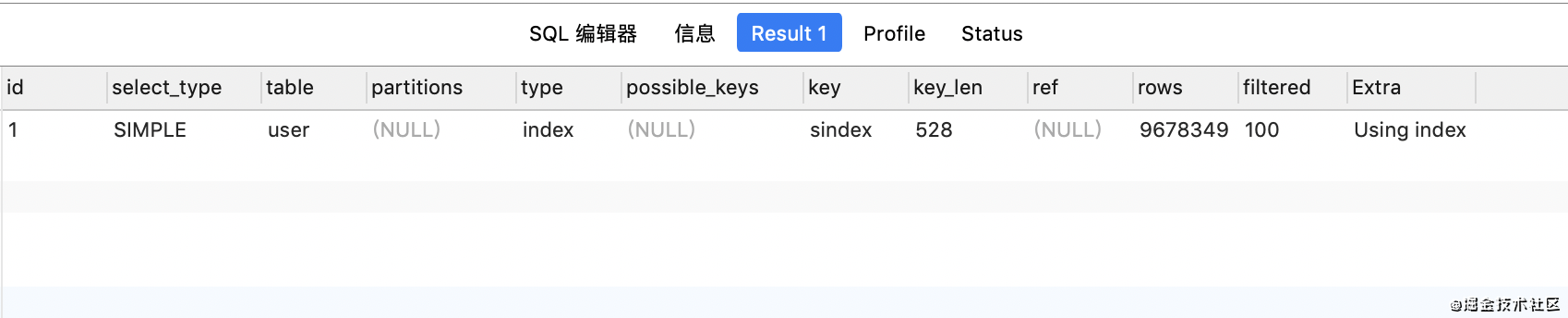
看上面的執(zhí)行計劃�����,雖然type是從all->index,走了sindex索引�,但是實際上查詢速度并沒有發(fā)生改變���。
其實��,創(chuàng)建聯(lián)合索引���,是為了有條件查詢的時候速度更快,而不是全表查詢
select * from user where uname='6.445329111484186' //3.5s(無聯(lián)合索引)
select * from user where uname='6.445329111484186' //0.003s(有聯(lián)合索引)
所以這就是有聯(lián)合索引和無索引的差距
這里基本上可以證明����,加了索引和不加索引,進行全表查詢的時候��,效率就是會很慢
既然索引這個結果已經(jīng)不好使了��,那就只能找其他方案了�����。根據(jù)我之前mysql面試里面講的,count我們可以單獨存儲到一個表里面
CREATE TABLE `attribute` (
`id` int(11) NOT NULL,
`formname` varchar(50) COLLATE utf8_bin NOT NULL COMMENT '表名',
`formcount` int(11) NOT NULL COMMENT '表總數(shù)據(jù)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;

這里說一下�����,這種表一般不會查所有�,只會查詢一條,所以建表的時候�����,可以建成hash
select formcount from attribute where formname='user' //幾乎不用時
count就進行優(yōu)化完了����。如果上面有選擇條件的話,就可以建立索引����,通過走索引篩選的形式來查詢�,這樣就可以不用讀這個count了。
那么���,count是沒問題了�,分頁查詢優(yōu)化要如何優(yōu)化呢?這里可以使用子查詢來優(yōu)化
select * from user where
id>=(select id from user limit 9000000,1) limit 10 //1.7s
其實子查詢這種寫法�,判斷id,其實就是通過覆蓋索引來查詢����。效率會大大增加。不過我這里測試是1.7s��,以前在公司優(yōu)化這方面的時候�,比這個查詢時間要低,大家也可以自己生成數(shù)據(jù)自己測試
但是如果說數(shù)據(jù)量太大了�,我還是建議走es或者進行一些默認選擇,count可以單獨列出來
至此���,一個千萬級的數(shù)據(jù)分頁查詢的優(yōu)化就完成了��。
總結
到此這篇關于MySQL千萬級數(shù)據(jù)表優(yōu)化的文章就介紹到這了,更多相關MySQL千萬級數(shù)據(jù)表優(yōu)化內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- 詳細聊聊MySQL中慢SQL優(yōu)化的方向
- 淺談MySQL之select優(yōu)化方案
- Mysql縱表轉換為橫表的方法及優(yōu)化教程
- MySql子查詢IN的執(zhí)行和優(yōu)化的實現(xiàn)
- 帶你快速搞定Mysql優(yōu)化
- mysql 數(shù)據(jù)插入優(yōu)化方法之concurrent_insert
- mysql優(yōu)化之query_cache_limit參數(shù)說明
- MySQL優(yōu)化之如何寫出高質量sql語句
- mysql查詢優(yōu)化之100萬條數(shù)據(jù)的一張表優(yōu)化方案
- MYSQL 的10大經(jīng)典優(yōu)化案例場景實戰(zhàn)
